Join 알고리즘 대표적 3가지
시리즈 목차
(현재글) 1. Join 알고리즘의 종류
2. Join 알고리즘 최적화
Join을 포함한 쿼리가 실행될 때 데이터베이스 프로세서는 지금 디비 상황에 맞는 join 알고리즘을 선택해야 한다. 대표적인 3가지를 알아보자.
Nested Loop Join
이름 그대로 중첩 loop 방식으로 조건에 맞는 데이터를 찾는다. 중첩 for문이라고 생각하면 된다. 첫번째 테이블에서 데이터를 하나 선택하고 두번째 테이블을 선회하면서 둘의 조인키를 확인하며 조건이 맞는지 확인한다. User와 School 테이블이 있고 서로가 userId로 조인된 상태라면 아래 처럼 작동한다.
1
2
3
4
5
6
7
for (const user of users) { // 첫번째 Loop
for (const school of schools) { // 두번째 Loop
if (user.schoolId === school.id) { // 두 테이블의 데이터를 가져왔으니 조인 조건 확인.
pushToResultArray(user, school) // 조건이 맞다면 결과에 추가.
}
}
}
이렇게 하면 복잡도가 n제곱이라서 성능상 좋지않은거냐고 할수 있다. 맞다. 그래서 많은 양의 데이터를 검색할때는 성능이 좋지않다. 그런데 대부분의 쿼리에는 where절이 있기때문에 최대한 loop에 돌아가는 범위를 줄이게 된다. where로 데이터 범위를 줄일수 없다면 데이터베이스가 알아서 다른 join 알고리즘으로 변경하여 성능을 최적화한다.
Hash Join
Hash Join은 두 테이블이 조인하는 특정 값을 이용한다. 둘이 같은 값을 가지고 있기 때문에(user, school이라면 user가 schoolId를 가지므로 같은 값을 가짐.) 같은 해시 함수를 실행하면 같은 응답값이 나오는 걸 이용하는 것이다.
먼저 해시 테이블을 만든다. 조인된 두 테이블 중 사이즈가 작은 테이블을 찾는다. 그리고 작은 사이즈의 테이블로 해시테이블을 만든다. 해시 테이블의 키는 조인에 이용되는 값을 해시 함수 실행시켜 얻은 값이다. 해시 테이블의 값은 해당 열이다. 해당 열의 일부분이 될수도 있고 전부가 될수도 있다. 혹은 해당 열의 메모리 주소값일수도 있다.(메모리 주소로 값을 저장하면 추후에 메모리 주소로 다시 접근하여 데이터를 얻어야하는 단점이 있다.)
데이터가 아래와 같다면
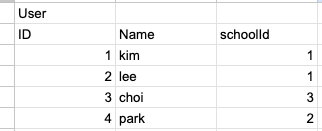
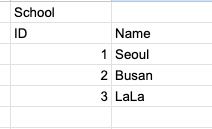
먼저 School테이블이 사이즈가 더 작기때문에 School 테이블을 이용하여 해시 테이블을 만든다. User와 School 테이블은 schoolId로 서로 조인하고 있기 때문에 School.id를 해시함수 실행시켜 키 값을 설정한다. 그리고 해시 테이블의 값으로는 해당 열 데이터의 일부를 저장한다. 예시에서는 school 데이터의 ID를 저장한다.
‘aaa1’은 1을 해시함수 돌린 값, ‘aaa2’는 2를 해시함수 돌린값이라고 생각하자.

이제 나머지 테이블(크기가 좀더 큰 테이블: User)에서 작업을 시작한다. User 테이블을 순회하여 School과의 조인을 나타내는 값을 해시 함수 실행시킨다. 해시 함수 실행 결과 값을 해시 테이블과 매칭해서 같은 값이 있으면 해당 테이블과 결합시킨다. 그리고 결과 목록에 추가한다. User 테이블에서 순회를 마치면 결과 목록이 완성된다.
대략 코드로 표현하면 이렇다.
1
2
3
4
5
6
7
8
9
10
const smallerTable = findSmallerTable(Users, Schools);
const biggerTable = Users === smallerTable ? Schools : Users;
const hashTable = createHashTable(smallerTable);
for(const eachRow of biggerTable) {
const joinedTable = findMatchingDataFromOtherTable(hashFunc(eachRow.joinKey))
return pushToJoinResult(joinedTable, eachRwo)
}
Merge Join
Merge 조인은 조인되는 두 테이블을 각자 조인키 값을 기준으로 정렬시킨다.
| USERS | ||
|---|---|---|
| id | name | scholl_Id |
| 1 | kim | 3 |
| 2 | lee | 1 |
| 3 | choi | 2 |
| 4 | lim | 6 |
| SCHOOLS | |
|---|---|
| id | name |
| 1 | seoul |
| 2 | busan |
| 4 | lala |
위 값으로 Merge 조인을 한다면
- 개별 테이블이 공유하는 조인키로 정렬된다.
아래를 보면 USERS가 school_id로 정렬된 걸 확인할 수 있다.
| USERS | ||
|---|---|---|
| school_id | name | id |
| 1 | lee | 2 |
| 2 | choi | 3 |
| 3 | kim | 1 |
| 6 | lim | 4 |
| SCHOLLS | |
|---|---|
| id | name |
| 1 | seoul |
| 2 | busan |
| 4 | lala |
(School id로 정렬된 두 테이블)
- 이제 두 테이블을 맨위 부터 비교하며 조인 키값이 같은 데이터들을 찾는다.
첫번째 비교
| USERS | |||
|---|---|---|---|
| school_id | name | id | pointer |
| 1 | lee | 2 | O |
| 2 | choi | 3 | |
| 3 | kim | 1 | |
| 6 | lim | 4 |
| SCHOLLS | ||
|---|---|---|
| id | name | pointer |
| 1 | seoul | O |
| 2 | busan | |
| 4 | lala |
같은 키로 정렬된 상태이므로 바로바로 같은 조인키 값을 가진 데이터들을 찾을수 있다. 같은 포인터 위치의 데이터끼리 조인키를 비교한다. 값이 같다면 둘의 데이터를 병합하여 결과 데이터에 추가한다. 그리고 두 테이블 모두 포인터를 다음번 데이터로 옮긴다.
두번째 비교
| USERS | |||
|---|---|---|---|
| school_id | name | id | pointer |
| 1 | lee | 2 | |
| 2 | choi | 3 | O |
| 3 | kim | 1 | |
| 6 | lim | 4 |
| SCHOLLS | ||
|---|---|---|
| id | name | pointer |
| 1 | seoul | |
| 2 | busan | O |
| 4 | lala |
두번째 비교에서도 바로 포인터에 있는 데이터들이 조인키가 같다. 결과 목록에 병합하여 추가한다.
세번째 비교
| USERS | |||
|---|---|---|---|
| school_id | name | id | pointer |
| 1 | lee | 2 | |
| 2 | choi | 3 | |
| 3 | kim | 1 | O |
| 6 | lim | 4 |
| SCHOLLS | ||
|---|---|---|
| id | name | pointer |
| 1 | seoul | |
| 2 | busan | |
| 4 | lala | O |
세번째에 와서야 포인터에있는 값들이 조인키가 맞지않다. 이럴 때는 조인키를 비교하여 작은 값을 가진쪽에서 포인터를 다음으로 옮긴다.
네번째 비교
| USERS | |||
|---|---|---|---|
| school_id | name | id | pointer |
| 1 | lee | 2 | |
| 2 | choi | 3 | |
| 3 | kim | 1 | |
| 6 | lim | 4 | O |
| SCHOLLS | ||
|---|---|---|
| id | name | pointer |
| 1 | seoul | |
| 2 | busan | |
| 4 | lala | O |
이번에도 포인터들의 조인값을 비교해봤지만 같지 않다. 그런데 이번에는 조인값이 작은 쪽에서 더이상 다음 값으로 옮길수가 없다. 이러면 더이상 매칭할 데이터가 없는 것이기 때문에 탐색 과정이 끝난다. 그리고 병합된 데이터를 리턴한다.
이때 Join 방식에 따라(inner, left, right, full etc..) 매칭되지않은 데이터들에 대해 null을 한쪽 테이블 데이터는 null을 설정해서 결과값에 추가할지 두 테이블 데이터 모두 보여주지않을지 결정하게 된다.
다음 글에서는 이 3가지 알고리즘의 최적화에 대해 알아보자.